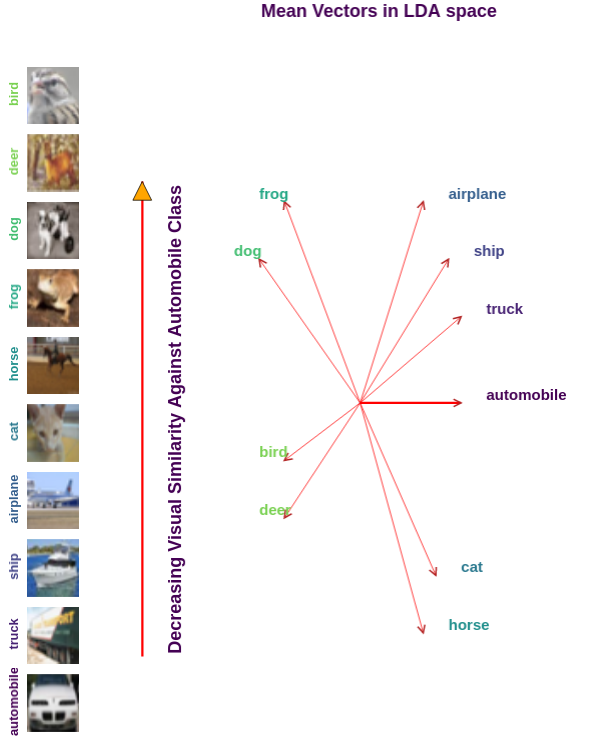
 Traditionally artificial neural networks (ANNs) are trained by minimizing the cross entropy between a provided ground truth delta distribution (encoded as one-hot vector) and the ANN’s predictive distribution. However, it seems unacceptable to penalize networks equally for misclassification. Confusing the class “Automobile” with the class “Truck” should be penalized less than confusing the class “Automobile” with the class “Donkey”. To avoid such representation issues we present a variation of cross entropy loss utilizing a mixture between a probabilistic prior belief for samples and the ground truth. To demonstrate our technique we construct such a similarity measure using Linear Discriminant Analysis. We then apply the new formulation to multiple deep convolution neural networks (CNNs) for object classification tasks and empirically show a 3% to 12% improvement against networks using the traditional loss formulation.
Traditionally artificial neural networks (ANNs) are trained by minimizing the cross entropy between a provided ground truth delta distribution (encoded as one-hot vector) and the ANN’s predictive distribution. However, it seems unacceptable to penalize networks equally for misclassification. Confusing the class “Automobile” with the class “Truck” should be penalized less than confusing the class “Automobile” with the class “Donkey”. To avoid such representation issues we present a variation of cross entropy loss utilizing a mixture between a probabilistic prior belief for samples and the ground truth. To demonstrate our technique we construct such a similarity measure using Linear Discriminant Analysis. We then apply the new formulation to multiple deep convolution neural networks (CNNs) for object classification tasks and empirically show a 3% to 12% improvement against networks using the traditional loss formulation.Deep Learning for Visual Object Recognition
Traditionally artificial neural networks (ANNs) are trained by minimizing the cross entropy between a provided ground truth delta distribution (encoded as one-hot vector) and the ANN’s predictive distribution. However, it seems unacceptable to penalize networks equally for misclassification. Confusing the class “Automobile” with the class “Truck” should be penalized less than confusing the class “Automobile” with the class “Donkey”. To avoid such representation issues we present a variation of cross entropy loss utilizing a mixture between a probabilistic prior belief for samples and the ground truth. To demonstrate our technique we construct such a similarity measure using Linear Discriminant Analysis. We then apply the new formulation to multiple deep convolution neural networks (CNNs) for object classification tasks and empirically show a 3% to 12% improvement against networks using the traditional loss formulation.